













What is a Web Site?
A web site is a collection of pages on the World Wide Web that share a common Uniform Resource Locator (URL). For W&M, the top-level URL (or "host name") is https://www.wm.edu. The W&M site contains many smaller sites and sub-sites. For us, these smaller sites are contained within a system of folders in our Content Management System, Cascade. The folder names dictate the sites' URLs. For example, web pages that start with https://www.wm.edu/as/english/ make up the English Department's web site.
Uniform Resource Locator
Everything on the web has it's own unique location. Every. Little. Thing. The URL is an identifier/location for items on the World Wide Web. Every URL has specific parts:
https = HyperText Transfer Protocol Secure - this specifies the way in which the server will send the file and how the browser will display it.
www - World Wide Web. The World Wide Web is the combination of all resources on the Internet that are connected using HTTP. Even though we sometimes use the terms interchangably, note that not everyting on the Internet is on the World Wide Web. For example, your desktop email client works through the internet, but is not on the Web.
Host Name: W&M's host name is wm.edu
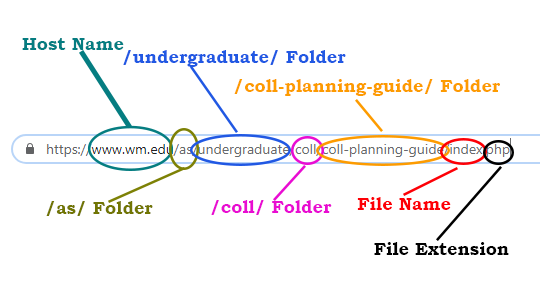
Location information: Everything after the host name and before the "." of the file type (for English's main page, it's "as/english/index") . This tells the server where to find the specific item you want to see. In Cascade, we use folders and filenames to identify items on our website. The folder names and filenames become part of the item's URL.
File type: When Cascade publishes, it turns Cascade database files into .php files. We also use image files: .jpg, .png, or .gif; or document files: .pdf. This extension lets the browser know how to display the file.
How it works (basically)
Why you sometimes have to create several different files for one web page.
When you enter a URL into your browser, or click on a link, this sends a message to the computer that is hosting the website: the server. The message is essentially the address of the file you want to see. The server finds the file, then pushes it out to your browser. The browser uses the information in that file to decide how to display the information you want.
This is pretty simple for web pages that just contain text. But, if you have a web page that conains an image, that image is separate from the page - it has it's own URL. So, when your browser is displaying a page with an image, it starts displaying the text, and when it comes to the bit of code for the image, it has to go back to the server, request the image, then place that image in the correct spot on the page.
It gets more complicated for pages that display things like our events listboxes: the browser will start to display the page, but then it has to go back to the server to fetch the file that is the listbox. It will add the box part to the page, but then go to events.wm.edu to get the relevant upcoming events, and place them in the box part of the listbox.
That this all happens so fast we hardly notice it still seems like magic to me.
More Information
- Mozilla's How the Web Works
